はじめに
こん〜!
今回は、いつかやろうと思っていた Meta(Facebook) 広告上でばら撒かれまくっている悪性広告を自動検出する試みについて、 うまくいったこと・いかなかったこと・考察等をまとめていこうと思います。
先にまとめ
- Facebook の GraphQL API だと、検索できる広告タイプが限られており、 Graph API を用いた自動化は(現在は)できない
- 広告ライブラリAPI という Web Page 機能 からの API サーチだと広告の検索が可能であり、悪性広告を検索可能
- 広告ライブラリAPI からの検索は、(多分)全文検索だと思われるので、特定のキーワード・ドメインをキーワードとした検索が可能
- 作成したカスタムクエリの一つは、検索結果の20件が全て悪性広告であった
- 広告の先が悪性なECサイトであるかを判定する方法として、robots.txt を参照する方法を考案して実施した
- Meta の広告審査方法はもう少し頑張っていただいて、よりよりプラットフォームになってほしい
そもそも Meta/Facebook 広告って?
Meta 広告は、ユーザーが広告を出稿することができるプラットフォームで、 このサービス上で広告を出すことで、以下のサービスに広告を掲載することが可能です。
この Audience Network というのは、以下のブログによると、 Meta 社のサービス以外にも広告が配信されるようです。
引用元: FacebookのAudience Networkってどこに配信されるの?ターゲティング設定と動画広告の相性抜群でクリック率が静止画広告の2倍にUP!
https://www.akindo2000.net/blog/facebookaudiencenetwork/
グノシー、C CHANNEL、東洋経済ONLINE、現代ビジネス、weblio、Baidu dメニュー、auスマートパス、ジョルダン乗換案内、食べログ、Retty、 SEGA、A TEAM、mobage、Zaim(ザイム)、ジモティー、マンガボックス、漫画BANG など
しかしながら、この Facebook Ads は、自分が観測した限りかなり悪性広告が出稿されている状態にあります。
例えば、以下のような感じで悪性広告が掲載されます。 そして、被害者はそれらをクリックすることで、偽ECサイトに誘導されていきます。
#詐欺広告 in #facebook #instagram #meta #ads #scam #phishing
— Osumi, Yusuke (@ozuma5119) 2022年11月15日
ad ID: 5697061973716791
> ビジネスのニーズに合あった製品を、最新のデバイスセレクションからお選びください。
LinkTo: hxxps://optizfail[.]live/https://t.co/beAsdgGffz
Brand: Dell
👾 displayed on the Facebook's Timeline pic.twitter.com/1In94JAgbs
厄介なのが、これらの偽EC サイトはかなりの種類のデザインテンプレート(おそらく盗用)が用意されている点です。 一般ユーザーがこれらを常に偽物か本物かを見抜き続けて回避するのは難易度がとても高いはずです。
また、一般のユーザーが「いつも使っているサービス上に悪性広告が出る場合がある」と 明確に認識していない(経験値が少ない)点も重要です。 「詐欺メール・詐欺SMSが届いた」とよく耳にしたり、体験している人も多いと思いますが、 偽広告を踏むケースはそれらに比べて圧倒的に少ないです。 つまり、ユーザー側の警戒心が低い部分かもしれないということです。
もちろん、「サイトが重いなー」「流石にこれは安すぎて怪しい」等の要素で気がつけるユーザーもいると思いますが、 上記の理由などによって、運悪く騙されるユーザーは結構いるはずです。
悪性広告の例を見てみる
自動検出する方法の前に、そもそも偽広告がどういう感じなの?と思われる読者の方もいらっしゃると思うので、一つ例示します。
※自分が調べた限り、多分複数のフィッシングアクターが存在するため、全てこれから例示するサイトのようになっているというわけではないと思います。
悪性広告は、以下のような画像やテキストを広告として出稿していることがあります。
広告:
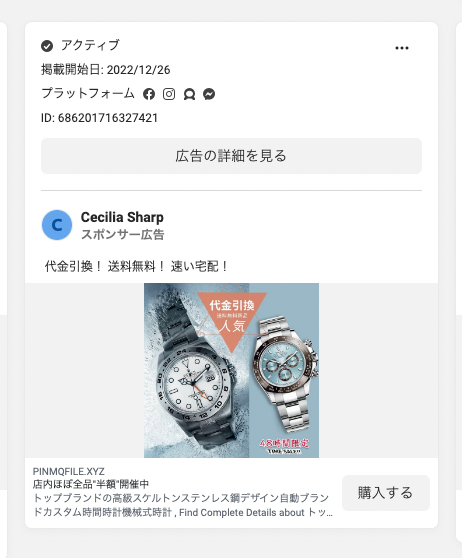
これらの画像をクリックすると、以下のような偽ECサイトに着きます。
ページのトップ画面・偽物の商品・購入画面:
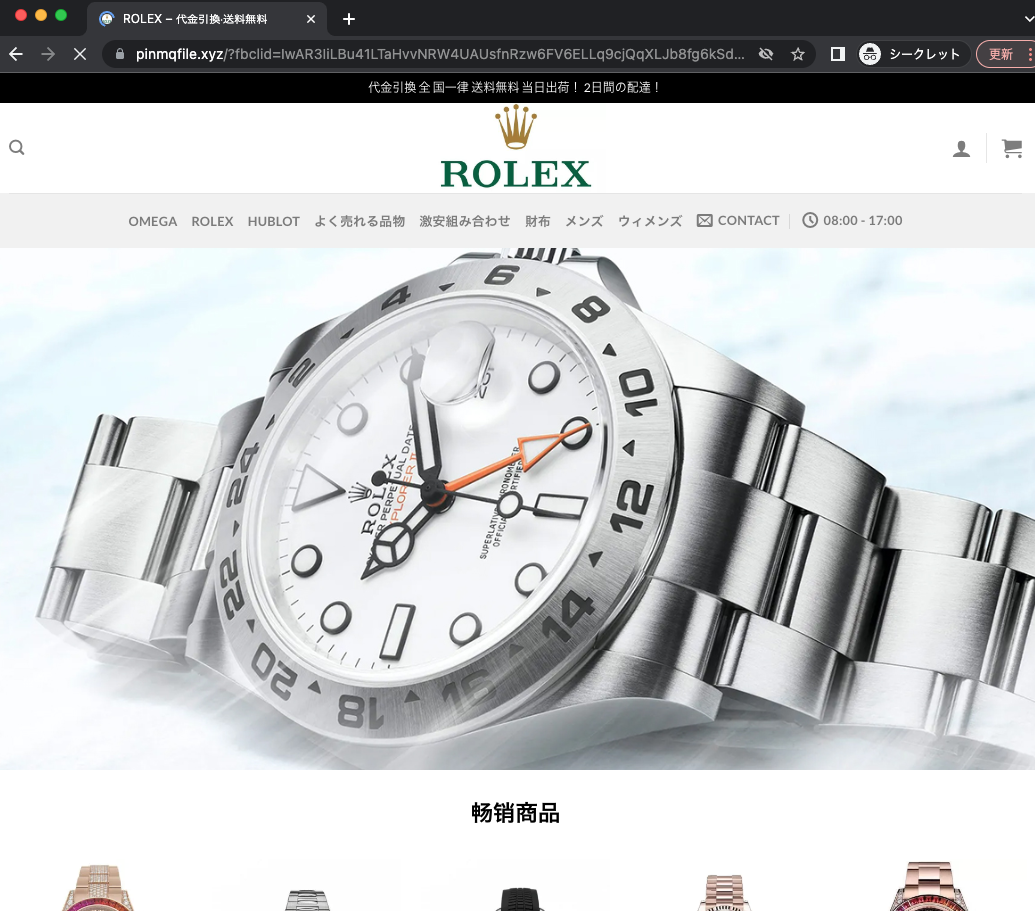

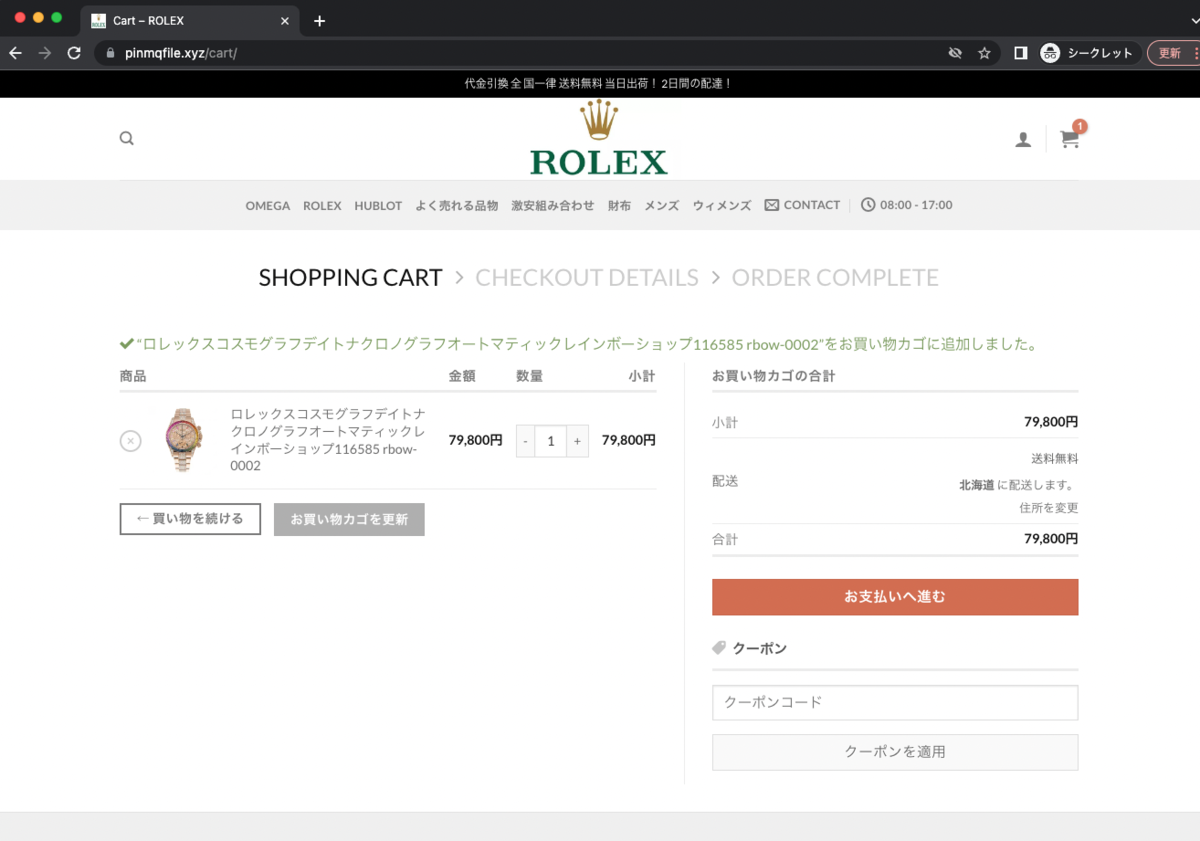
偽EC サイト URL: pinmqfile[.]xyz
立ち上がり時期: 11/23 - 11/26 あたり
利用しているシステム構成: Wordpress / Cloudflare
定番の構成はこれらのように、Wordpress などの定番CMSを利用し、 Cloudflare 等で防弾的に利用して被害者が騙されるのを待っていたりします。
また、大抵の場合は Let's Encrypt あたりを利用しています。
傾向としては商品の値段が 60-90% 引きだったりして異常な値段だったりするのも特徴です。 「明らかに安すぎるだろ」と思えてしまうのですが、おそらくこのくらいの値引きが一番騙しやすいんじゃないのかなーと思います。 というのも、彼らもビジネス(?) でやっているので、結構なPDCAを回しているはずで、そんな彼らが設定する値ということは、 おそらくこの価格帯が一番効果があるのだと思われます。
悪性広告ハンティング
さて、ここからが本題です。 実は Meta が提供するサービス上で、広告一覧を検索できるシステムが存在します。 先ほど例示したサイトの広告はこのページから引っ張ってきました。
https://www.facebook.com/ads/library/
このサービスは Meta が提供している出稿済みの広告を検索できるシステムです。 更に API として GraphQL の API も提供されているため、これらを利用して悪性広告をどうにか検出してみます。
広告ライブラリAPI で、検知用クエリを組む
自動化する前に、そもそも悪性広告をどのように検索するか、いくつか案を出してみましょう。 パッと浮かぶ案としては以下があります。
- 悪性広告が出ている日付をキーにしてどうにか検索する
- 悪性広告のよく使う単語をキーにする
- 悪性広告を投稿するユーザーをどうにか検索する
- 悪性広告が使う画像をどうにか分類したりして検索する
- etc...
案自体はいっぱい出てきますが、残念なことに殆どは「広告ライブラリ」のサービスでは適用できません。
検索に使えるパラメータは、画像にあるように、以下の項目 ( + 自由分検索のキーワード)のみです。
- 言語
- 広告主 (広告出稿者のユーザ名)
- プラットフォーム (e.g. Facebook, Instagram など)
- メディアタイプ (画像・ミーム(テキストや画像に含まれる文字)動画、動画などを含まない形式等)
- オンラインのステータス(広告の状態。アクティブ・非アクティブなど)
- 広告の開始日・終了日
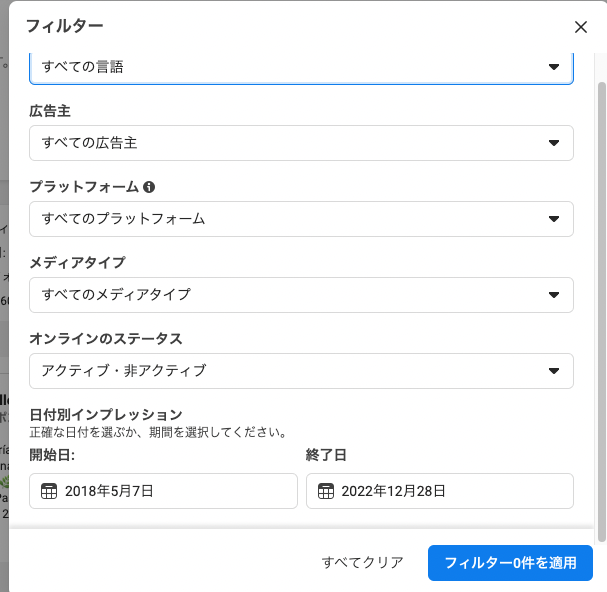
いくつか、合わせれば悪性広告を検索できそうですが、かなりのチューニングを行い、 このサービス自体の癖や、アクターごとの癖を推察して適用しないとダメそうです。とっても大変です。
試しに「時計」とだけで調べてみると、20件中で悪性広告は0件でした。 これらの(悪性広告を検索するには)貧弱なパラメータ群を利用して、悪性広告を検出するのは至難の業です。
そこで、いいアプローチは無いかとあーでもない、こーでもないと考えていたところ、あるアプローチが思いつきました。 それは「全文検索なら、URL とかも検索対象だったりするのでは?」というものです。
そこで、悪性広告で比較的よく使われていた cyou (トップレベルドメイン) で検索してみます。
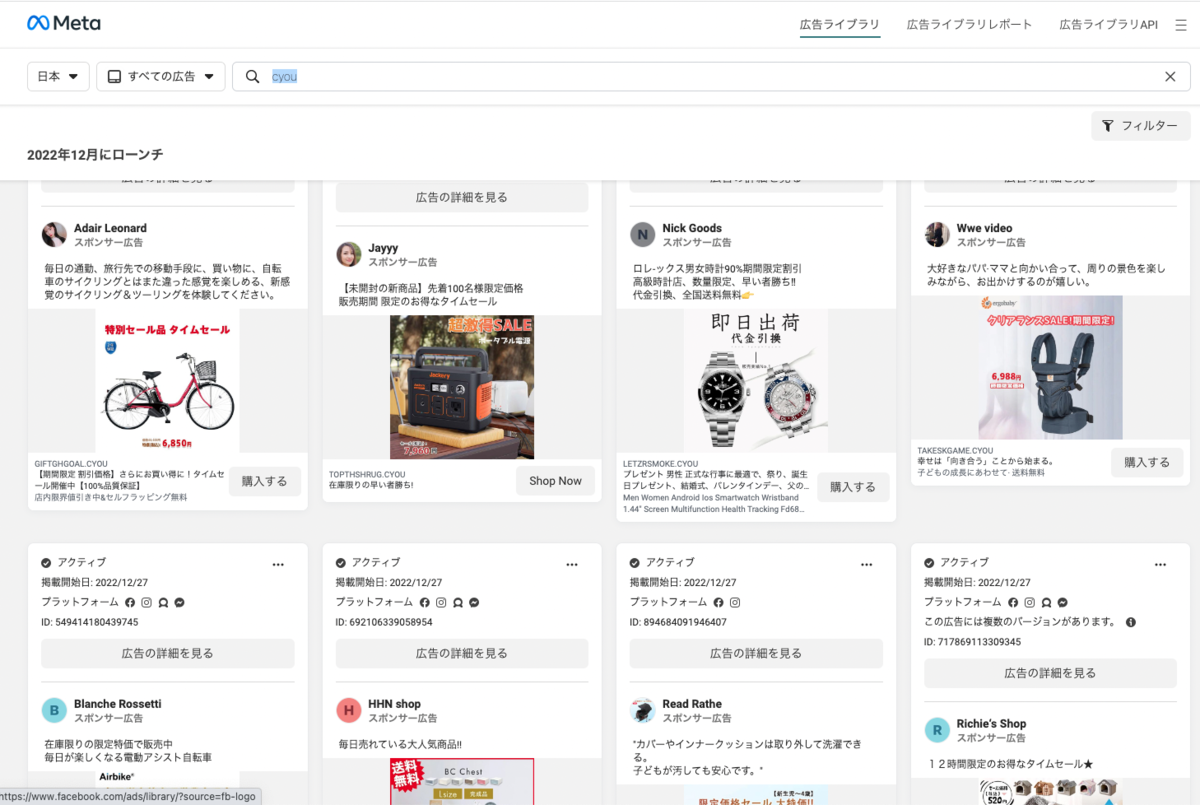
キタ━━━(゚∀゚)━━━!!
悪性広告のバーゲンセールです。完璧なアプローチです。 あとは、この中から「通常の広告」と「悪性広告」を見分ける手法を考えるだけです。
通常の広告・悪性広告を見分ける
通常の広告・悪性の広告の違いは「リンク先がフィッシングサイトであるかどうか」で判断されます。つまり、広告を見ただけで判断することはできません。
そこで、いくつかの特徴を調べていったところ、自分の中で確度が高く、悪くないアプローチが思いつきました。 それは、「悪性広告を利用するアクターがやりがちな、Google Index 避けの設定」です。
実は、この Meta の悪性広告を使っているアクターの多くは、以下のような robots.txt をよく配置しています。
User-agent: * Disallow: /
これは、全てのクローラーに対して「全ページ Index するな」という指定です。
おそらく以下の意図から設定しているのではないかと思います。
もちろん推測なので、どういう意図で設定しているか、真意は不明です。
しかし、一つだけ言えることは「通常の開発者が設定する robots.txt にしては異常すぎる」ということです。
というのも、 Meta にわざわざ広告を出稿するくらい SEO に意識がある人が、こんなゴミみたいな robots.txt を配置するでしょうか? するわけがないです。(誤ってやったというケースはあるかもしれませんが。)
そこで、今回はこれを判定材料に悪性広告と普通の広告を見極めてみようと思います!
※仮にこのアプローチが封じられても、アクターごとに使い回しているファイルとかを hash 突合すれば良いだけなので、このアプローチ以外でも判定自体はそこまで難しくないはずです。
自動化をする
検索方法、判定方法は整ったので、お次は自動化です。 既に GraphQL API などが存在しているということはわかっているので、ここは難航しないでしょう。(難航しました)
GraphQL API を利用する
結論から書いてしまいますが、 GraphQL API のアプローチは失敗しました。
API を利用するには本人確認が必要らしいので重い腰を上げて免許証の画像を送り、審査終了後に検索をしてみました。
しかし、検索の Requst を投げてみたり調査を進めていったところ、API Doc や Response に以下の記載がありました。
ad_type enum {POLITICAL_AND_ISSUE_ADS} ... デフォルト値: "POLITICAL_AND_ISSUE_ADS" The type of ad. We label either all returned ads as political or issue ads, or label ads for news related to politics or issues of political importance. See Facebook Ads Help Center, About ads related to politics or issues of national importance. We currently only support POLITICAL_AND_ISSUE_ADS.
なんと、この GraphQL API で利用できるのは POLITICAL_AND_ISSUE_ADS (社会問題、選挙または政治関連)という広告カテゴリのみのようです。
そのため、通常の広告カテゴリの検索することはできないようです。敗北。
広告ライブラリAPI (Web Page)を利用する
GraphQL API の方式は失敗してしまったので仕方がありません。 今度は Web App 上を使って、半自動で悪性広告を調べるアプローチをやってみます。 (当初の目的は自動化でしたが、目標を下方修正して、半自動化にします・・・)
Selenium とかで制御するアプローチも考えましたが、あくまで軽いリサーチで始めたのでそこまでは行いません。
まず、手動でページをスクロールしまくり、広告のデータを読み込みまくります。
お次に、ブラウザの DevTool から、以下のようなリンク収集用の JS を貼り付けて実行します。
var elements = document.querySelectorAll('a[href*="https://l.facebook.com/l.php?u="]') results = [] elements.forEach(e => { var rawUrl = e.getAttribute("href") var base64EncodedUrl = rawUrl.split("?u=")[1] var urlWithQueryParam = decodeURIComponent(base64EncodedUrl) results.push(urlWithQueryParam.split("?")[0]) }); // remove duplicate results = results.filter((element, index) => results.indexOf(element) === index); console.log(results)
すると以下のような結果が得られる。
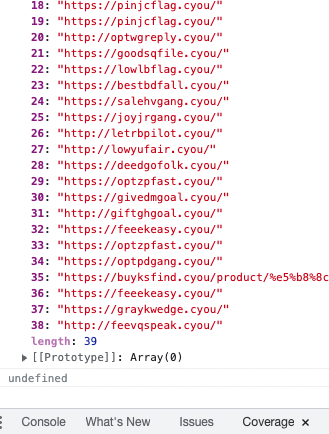
この結果を整形しつつ、以下の Python の urls の List に追加します。
import traceback from typing import List, Optional import requests urls = [] # FIXME def is_malicious_robot(robot: str) -> bool: if not "User-agent: *" in robot: return False if not "Disallow: /": return False if not len(robot.split("\n")) == 2: return False return True def get_random_user_agent() -> str: # TODO return "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" def get_robot(domain: str) -> Optional[str]: try: header = {"User-Agent": get_random_user_agent()} res = requests.get(f"https://{domain}/" + "robots.txt", headers=header) if res.status_code == 200: return res.content.decode('utf-8') else: return None except Exception: return None def main(urls: List[str]): domains = [] for u in urls: domains.append(urlparse(u).hostname) domains = list(set(domains)) # remove duplicate print(f"Domain Length: {len(domains)}") for d in domains: robot: Optional[str] = get_robot(d) if robot: if is_malicious_robot(robot): print(d) else: print(f"False: {d}") else: print(f"False: {d}") if __name__ == '__main__': main(urls)
さて、これを流してみた結果・・・
48/48個(多分ドメインの重複あり)で、悪性判定が出ました!素晴らしい。
とはいえ、 cyou のクエリ精度が良すぎただけかもしれません。
そこで今度は、精度が良くはなさそうな xyz で検索してテストしてみます。
結果は 49/136 が悪性判定でした。(ただ、中には既に死んでいるドメイン等もあるため、実際の数は増減があると思います)
.xyz というクエリ自体の精度はよく無いことが分かりましたが、
その後のフィルター処理(Python の部分)で行ったフィルターによって、確度の高そうな悪性ドメインを抽出できました。
(ただ、目で確認までしていないため、実際これらが本当に悪性であるかは、ある程度テストして精度確認する必要はあると思います)
まとめ
今回は Meta 広告上でばら撒かれている悪性広告 / 偽EC サイトの自動検出について、試してみました。 結果としてはかなりうまくいき、悪性広告を検出を半自動的に実施できるところまで持っていきました。
今回の調査結果を持って、 Facebook 側にはより広告審査を厳格にしていただき、安全なプラットフォームを提供してもらえたら嬉しいなと思っております。
また、冒頭に書いた通りですが、まとめとしては以下のような形となりました。
- Facebook の GraphQL API だと、検索できる広告タイプが限られており、 Graph API を用いた自動化は(現在は)できない
- 広告ライブラリAPI という Web Page 機能 からの API サーチだと広告の検索が可能であり、悪性広告を検索可能
- 広告ライブラリAPI からの検索は、(多分)全文検索だと思われるので、特定のキーワード・ドメインをキーワードとした検索が可能
- 作成したカスタムクエリの一つは、検索結果の20件が全て悪性広告であった
- 広告の先が悪性なECサイトであるかを判定する方法として、robots.txt を参照する方法を考案して実施した
- Meta の広告審査方法はもう少し頑張っていただいて、よりよりプラットフォームになってほしい
検知部分や、より良い検索クエリの探求、自動の通報処理など数々の課題はありますが、 是非これらを Meta 社自身が認知して対応を進めてくださることを切に願っております。